Energy Logserver – bezpieczeństwo infrastruktury
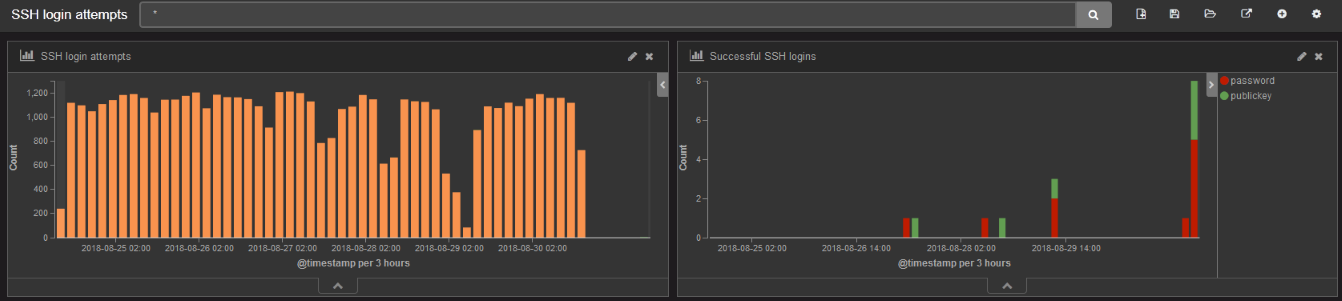
Spójrzmy na badanie bezpieczeństwa infrastruktury pod kątem analizy rejestru zdarzeń generowanego przez usługę SSHD. Plik /var/log/secure zawiera informacje związane z poświadczeniami i autoryzacją. SSHD zapisuje wszystkie generowane przez siebie informacje do tego właśnie pliku – między innymi nieudane i zablokowane próby logowania.

Dane z pliku secure są pobierane i przekazywane do Energy Logserver z wykorzystaniem programu Filebeat. Jego zadaniem jest podpięcie się pod zadany plik lokalny zawierający logi, agregacja tych danych (zmniejsza to ryzyko dziur jakie mogą powstać przykładowo przy zerwaniu połączenia z serwerem logów), a następnie przesyłanie ich we wskazane w konfiguracji miejsce.
Są one następnie analizowane w celu – przykładowo – ustalenia liczby i szczegółów dotyczących nieautoryzowanych prób logowania. Atak mógłby, po identyfikacji otwartych portów zostać przeprowadzony z wykorzystaniem standardowych lub popularnych nazw użytkowników. Poniżej tzw. chmura wygenerowana z wykorzystaniem nazw użytkowników jakimi posłużono się do prób logowania:

Na podstawie IP występujących w pliku „secure” można ustalić geograficzne źródła każdej próby. Służy do tego wtyczka sprawdzająca każdy wychwycony adres w bazie whois. Po takiej analizie do każdego dokumentu, który już zawiera IP są dodawane długość i szerokość geograficzna. Takie zabieg pozwala poznać i przeanalizować skąd pochodzą próby logowań do systemu. Następnie pozostaje naniesienie tych informacji na mapę z cieplnym oznaczeniem częstotliwości występowania danej lokalizacji w logach.

Bardzo ważną funkcjonalnością Energy Logserver jest moduł alarmujący. Istnieją różne typy zachowania modułu, przy czym najprościej w powyższym przykładzie wykorzystać typ opierający się o częstotliwość wystąpień. Określa się wówczas ile wystąpień dokumentu zgodnego z zadanym zapytaniem w danej jednostce czasu ma powodować wysłanie powiadomienia mailowego. Oczywiście można zamiast powiadomienia takiego uruchomić zdalny skrypt, który w reakcji na potencjalny atak mógłby odciąć dostęp do serwera w celu ochrony danych.

Przykłady typów na jakich można oprzeć raportowanie to:
– blacklist- alarm uruchamiany jest w momencie gdy wartość określonego pola zgodna jest z czarną listą,
– change – wartość danego pola ulega zmianie,
– flatline – ilość przychodzących dokumentów jest poniżej określonego progu,
– new term – wartość dla danego pola pojawia się w logach po raz pierwszy,
– any – najbardziej uniwersalny typ, w którym każde wystąpienie zgodne z określonym zapytaniem spowoduje uruchomienie alarmu.
Informacje pozyskiwane z logów mogą nie tylko przyczynić się do znalezienia przyczyn już przebytych problemów i ich analizy ale również uchronić systemy od potencjalnych zagrożeń w czasie rzeczywistym. Dlatego tak ważna jest wygodna, przystępna forma ich prezentacji, czy też możliwość automatycznego korelowania zdarzeń i szybkiego powiadamiania o zaistnieniu problemu.